

随着IT技术的发展,信息种类不断增多,数据类型不断丰富,系统拥有的数据飞速增长,大数据技术快速升温,受到越来越多的关注。如何对这些大数据进行快速处理和分析,充分挖掘这些数据背后的价值,已经成为目前行业发展的一个必然趋势。
Hadoop作为目前主流的开放式并行计算平台,但其在扩展性不足,容量无法独立扩展,计算存储分离问题急需解决;宏杉分布式存储创新性的在存储层替代了原有HDFS文件系统,数据无需迁移,即可实现大数据的存算分离,且系统统一管理,减少运维压力。采用宏杉分布式存储系统,在文件读取效率、存储利用率上明显优于HDFS。
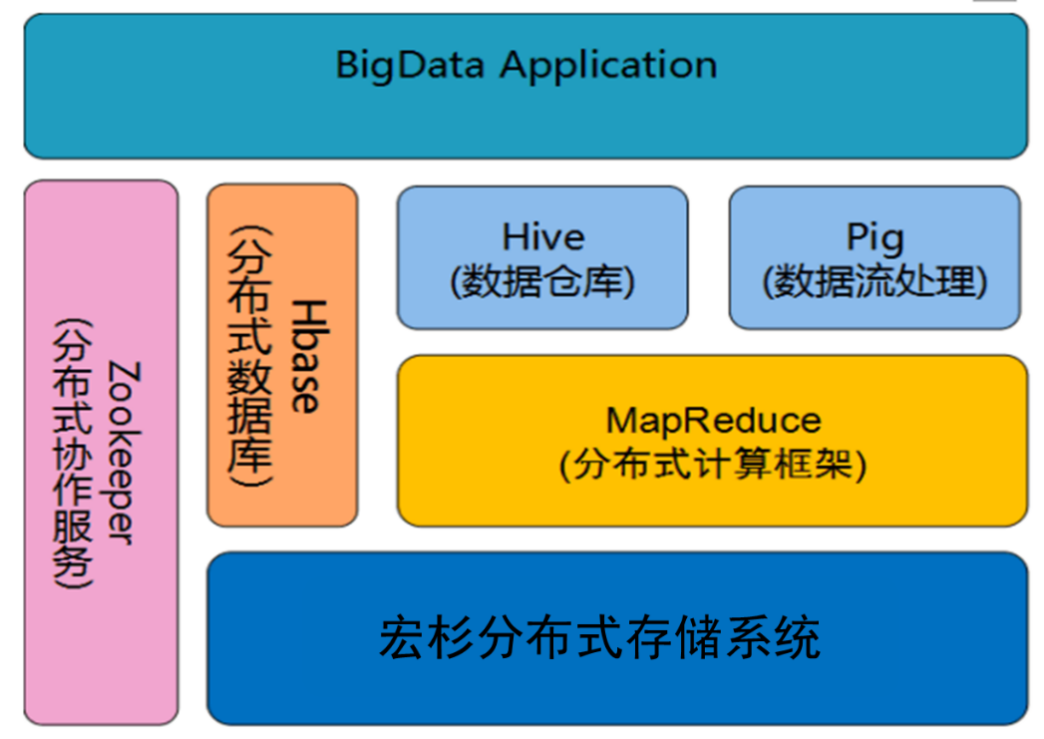
1. 存算分离部署
无缝对接hadoop平台,存储和计算资源按需扩展
2. 高数据读写性能
采用分布式架构,数据分散在多台服务器上,形成一个多对多数据访问通道,大大提升数据读写带宽
3. 丰富的数据保护特性
EC、多副本、双活、复制、多站点等多种数据保护特性,保证大数据平台数据的完整性
采用存储服务器集群的方式来满足海量数据的存储需求,能够为应用提供单卷EB的存储容量,且存储池中的资源可以按照应用性能和容量需求进行动态的弹性分配。
采用高效的索引数据库来满足海量文件数量的存储需求以及海量文件数量带来的元数据性能需求,可支撑千亿级文件的快速检索需求。
元数据与数据存储节点按需扩容,加大元数据检索能力与数据传输的性能,在高并发访问情况下,让数据存储端与访问端直接建立数据通道,进行并发数据读取,提升高并发访问效率。
